Project Goal
GPUs have become ubiquitous in scientific data processing and provide e.g. being a vast part of the computing power of modern High Performance Computing Centers (HPCs). The goal of the Madgraph5 project with Intel was to leverage the computing power provided by hardware accelerators through porting the software onto GPUs and other devices using the Intel SYCL/ oneAPI portability tool and to compare its performance against native programming APIs such as Cuda or HIP.
Background
The Madgraph5_aMC@NLO event generator software package is used for the simulation of particle collisions, e.g. in the context of high energy physics experiments at the Large Hadron Collider (LHC) at CERN. With the forthcoming upgrade of the LHC (HL-LHC) the forecasted recorded data volume is expected to grow by one order of magnitude which also implies a major increase in the need of simulated data. To cope with these increased needs for simulated data the software packages need to be improved in terms of performance via the offloading of the computations to hardware accelerator devices such as GPUs.
Progress
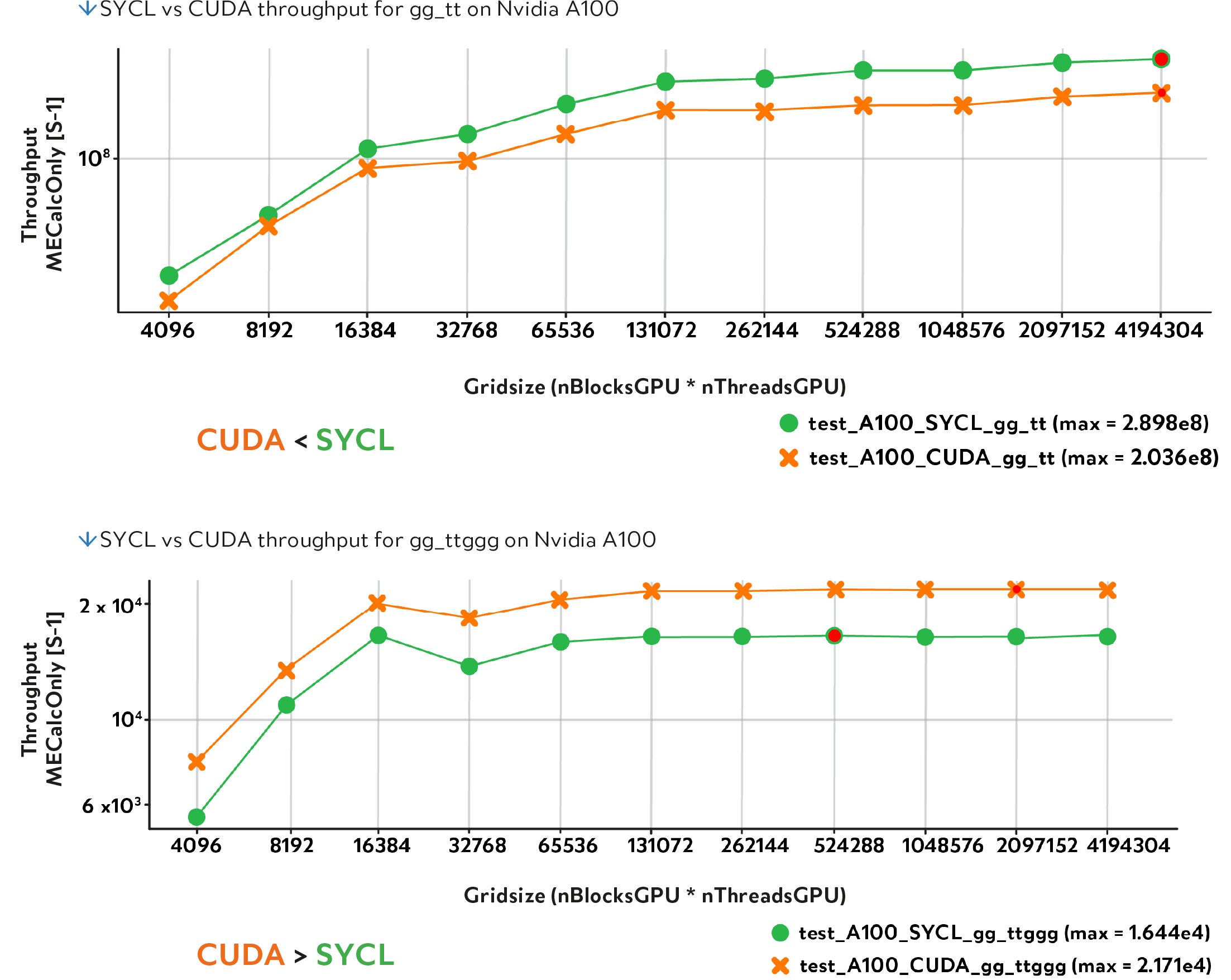
Madgraph5 is a versatile code generating tool which takes as input the physics processes to simulate and outputs source code (e.g. Fortran, C++, Python) to perform those simulations. Depending on the complexity of the underlying physics process the output may vary greatly in size and complexity. To cope with the forecasted needs for simulation at the HL-LHC, the compute intensive parts of the Madgraph5 software were re-engineered to output the Madgraph source code for parallel execution on GPUs via Intel SYCL/oneAPI as well as other native APIs. The porting of the code to SYCL started from the initial Cuda implementation in collaboration with University Catholique de Louvain and was first developed at CERN and later continued at Argonne National Labs. Together with the developments also a framework for automatic building and performance comparison of the software was put in place. The comparison was executed across over different physics processes with varying complexity and computing needs and across the different implementations of oneAPI/SYCL versus native GPU APIs and CPU implementations. The results of the performance comparison showed a better performance for oneAPI/SYCL over Cuda for simpler physics processes while Cuda outperforming oneAPI/SYCL for more complex processes.
Next Steps
The project ended in January 2023 with the published comparison results. The SYCL code will be integrated in the future within the main project together with native APIs.
Project Coordinator: Stefan Roiser
Technical Team: Jorgen Teig
In partnership with: Intel, Argonne National Laboratory, Université Catholique de Louvain